
Mar 19, 2018
Python日常小记 - 《风月》
起因
很久之前,我就曾经看到凤凰网《风月》专栏。这是一个主要介绍上世纪女明星的专栏,大致囊括了中外近100位知名女星的简要介绍和生平。
抛去收藏癖不谈,这个链接一直躺在我收藏夹里的原因,大概是我希望通过阅读这些简介,能够对这些曾经在演艺界举足轻重的明星有一点了解,在以后和“那个时代”过来人聊起来的时候不至于抓瞎。另外,简单看看这些不简单的女人们吧,或许能从她们身上找到一些我心目中对象应该有的特质?
总之,网页浏览体验太差,想着下载下来留存以后慢慢品鉴。
步骤
首先,明确目的。我希望能够把图片下载下来后一一转换合并为PDF文件,然后再合成一个整体的合辑,就像过去《收获》半年刊、《青年文摘》年刊一样,厚厚地存在硬盘里非常有踏实感。
所以第一个步骤便是了解这些图片访问的条件。所幸,凤凰网不是技术类网站而是媒体,很轻松就能获取到这些图片真实的链接。诸如伪造UA、Selenium、代理IP等等烦人的步骤皆可省去,可以方便地写出一份更注重过程的代码。
然后,通过观察图片链接所在位置,设计筛选器和正则匹配,得到链接。继续添加一些容错处理,一份运转良好的图片抓取脚本就写完了!
具体步骤
- 打开链接文件
- 循环读每一行,直接打开链接并截取链接日期部分
- 创建文件夹:第00x期+title+日期
- 循环下载图片:替换thumb部分内容,命名01-30
- 循环结束后:fpdf将图片合成一个PDF,文件名为第001期+title.pdf
- 创建文件夹:第00x期+title+日期
- 将所有PDF合成一个PDF
最后效果
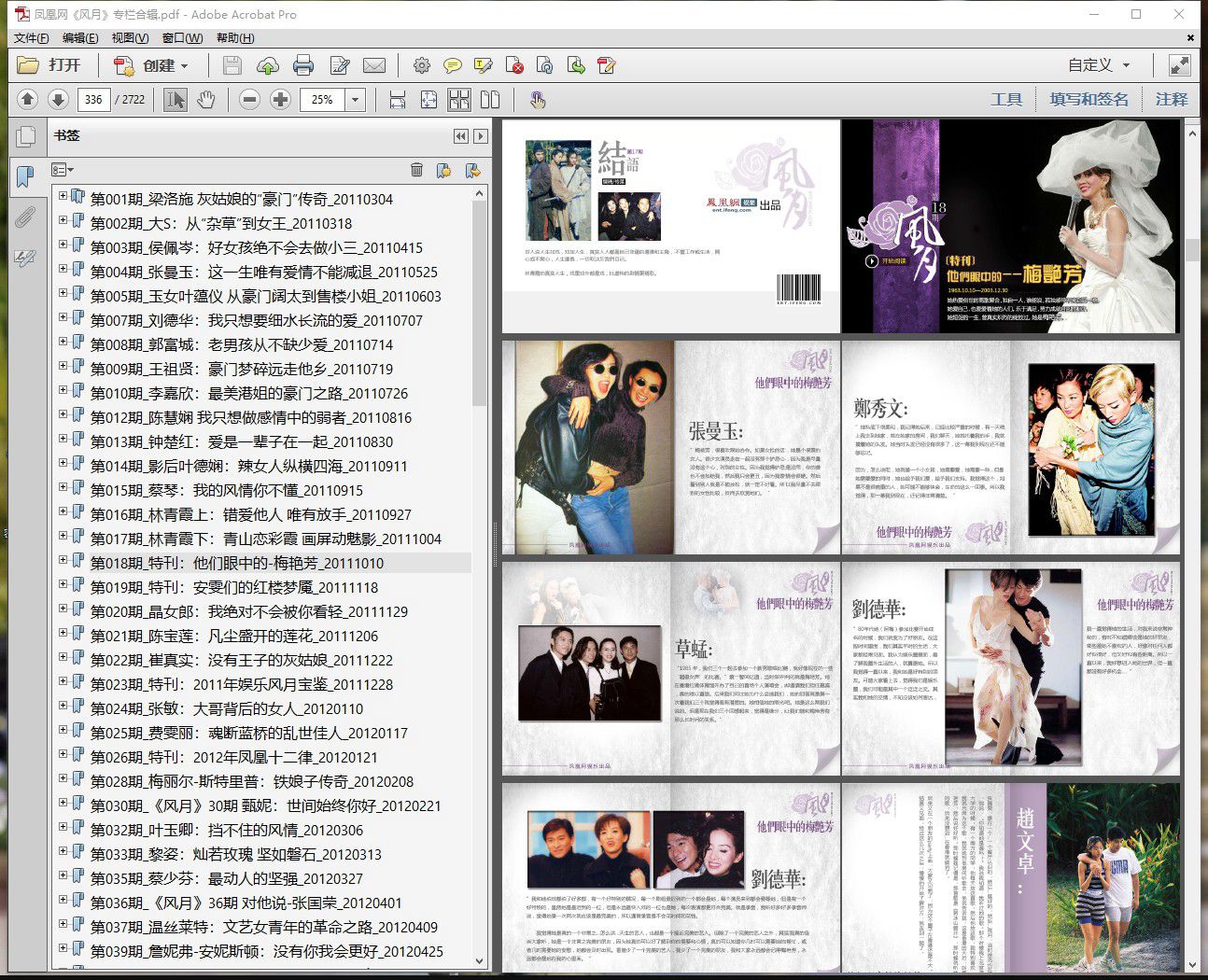
可以看到,将所有PDF合成后,Acrobat自动生成了书签跳转目录,非常方便。
使用方法和代码参见对应的Repo
问题与难点
没有什么难点,有一些不熟悉的地方需要查看文档。无非将设计好的步骤翻译成代码。或许所谓“业务逻辑”的工作就是天天干这些?
Leave a Comment